
Narzędzia programisty: Gulp
Ostatnio pisałem o automatyzacji. Jest to proces wymagający dobrania odpowiedniego narzędzia. Dzisiaj skupię się na jednym z nich - Gulp.
Gulp jest jednym z narzędzi służącym do automatyzacji. Strona projektu opisuje go jako streaming build system. W niektórych miejscach widnieje jako task runner. Zwał jak zwał. Wiele nazw na to samo. Gulp jest zwykle używany do automatyzowania webdevelopmentu. Prawdę mówiąc sam używam go do tego celu, jednak można go wykorzystać w dowolny inny sposób. Musisz mieć jedynie zbiór plików, na których chcesz operować oraz opis tego, co chcesz zrobić.
O tym dlaczego warto automatyzować pisałem w poprzednim poście.
Jak to działa?
Gulp jest narzędziem uruchamianym w środowisku node.js. Co prawda sens robienia aplikacji webowych w node jest mocno dyskusyjny, ale narzędzia na tej platformie są przemyślane. Gulp operuje na strumieniach. Oznacza to, że wszystkie stany pośrednie są przechowywane w pamięci, zamiast zapisywania np. tymczasowych plików na dysku. Gulp jest narzędziem konsolowym, jednak w świecie .NET zadania gulpa można go bez problemu uruchomić z poziomu Visual Studio (od wersji 2015). Gulpa można użyć do wielu zastosowań. Najpopularniejszymi z nich są:
- weryfikacja poprawności składni (lintery),
- transpilacja LESS/SASS -> CSS,
- transpilacja TypeScript/ECMAScript* -> JavaScript,
- minifikacja plików CSS/JavaScript/HTML,
- zmiana rozmiarów obrazków i optymalizacja kompresji,
- kopiowanie plików lub budowanie paczki przed deployem,
- deployowanie,
- czyszczenie zbudowanych plików.
Konfiguracja
Pracę z Gulpem rozpoczynamy od instalacji Node.js, npm i samego Gulpa. Node.js i npma najszybciej zainstalujemy za pomocą Chocolatey (Windows), Homebrew (macOS), apt-get (Linux) lub dowolnego innego managera pakietów.
# Windows
choco install nodejs.install
# macOS
brew install node
# Linux
# poradzicie sobie :-)Następnie przechodzimy do instalacji samego Gulpa. Gulp musi być zainstalowany globalnie w systemie oraz w samym projekcie. Przechodzimy do katalogu projektu, który będziemy automatyzować i wykonujemy:
npm init
# wykonujemy wszystkie kroki
# poszczególne wartości nie będą miały na nic wpływu
# możemy dusić [ENTER] aż do wyjścia z polecenia
npm install -g gulp
npm install --save-dev gulpMożemy teraz odpalić gulpa
$ gulp
[08:35:10] No gulpfile foundOczywiście polecenie się posypało. Nie mamy jeszcze opisu żadnego zadania, które chcemy wykonywać. Opis ten umieszczamy w pliku gulpfile.js.
gulpfile.js
Czas na zrobienie pierwszego zadania! Załóżmy, że chcemy zbudować pliki LESS z katalogu /src/less/, zminifikować je i umieścić w dist/css/. Chcemy, aby właściwości CSS były prefixowane w celu zapewnienia wsparcia w przeglądarkach 2 wersje wstecz. Będziemy potrzebowali do tego kilku pluginów. Z konsoli/terminala wykonujemy:
npm install --save-dev gulp-autoprefixer gulp-clean-css gulp-cleancss gulp-concat gulp-less gulp-lesshint gulp-load-plugins throughMamy wszystko, czego potrzebujemy. Teraz wystarczy dodać plik gulpfile.js:
var gulp = require('gulp'),
autoprefixer = require('gulp-autoprefixer'),
less = require('gulp-less'),
concat = require('gulp-concat'),
cleanCss = require('gulp-cleancss');
gulp.task('default', () => {
return gulp.src('src/less/*.less')
.pipe(less())
.pipe(autoprefixer({
browsers: ["last 2 version"]
}))
.pipe(concat('main.min.css'))
.pipe(cleanCss())
.pipe(gulp.dest('dist/css'));
});Teraz wystarczy uruchomić zadanie. Zadanie default jest domyślnym zadaniem gulpa, więc nie musimy podawać jego nazwy. Jeżeli jednak chcemy to zrobić, wpisujemy w konsoli/terminalu:
$ gulp default
[09:20:55] Using gulpfile ~/Workspace/gulptest/gulpfile.js
[09:20:55] Starting 'default'...
[09:20:55] Finished 'default' after 19 msW ten sposób wygenerował nam się plik main.min.css w katalogu dist/css/.
Był to bardzo prosty przykład. Przyjrzyjmy się czemuś odrobinę bardziej skomplikowanemu.
Zależność zadań
Chcemy zbudować aplikację składającą się z plików LESS, TypeScript i HTML. Chcemy wykonać poszczególne zadania:
- lintowanie (weryfikacja składni) plików LESS,
- lintowanie (weryfikacja składni) plików TS,
- budowanie plików LESS,
- budowanie plików TS,
- minifikacja zbudowanych plików CSS,
- minifikacja zbudowanych plików JS,
- minifikacja plików HTML.
Niektóre zadania są od siebie zależne.
Budowanie plików LESS nie ma sensu, dopóki nie przejdzie ich weryfikacja.
Należy przeanalizować, które z zadań mogą być zastosowane bez uruchamiania innych zadań. Zadania nie mogą przekazywać strumienia pomiędzy sobą. W celu przekazania danych pomiędzy zadaniami konieczne jest zapisanie plików na dysku, a następnie ich ponowne załadowanie.
Weryfikacja składni plików LESS ma sens jako osobne zadanie. Minifikacja plików LESS jest zawsze powiązana z ich budowaniem (możemy generować pliki .css i .min.css).
Żeby zauważyć zależności, najłatwiej będzie narysować skierowany pseudograf zadań:
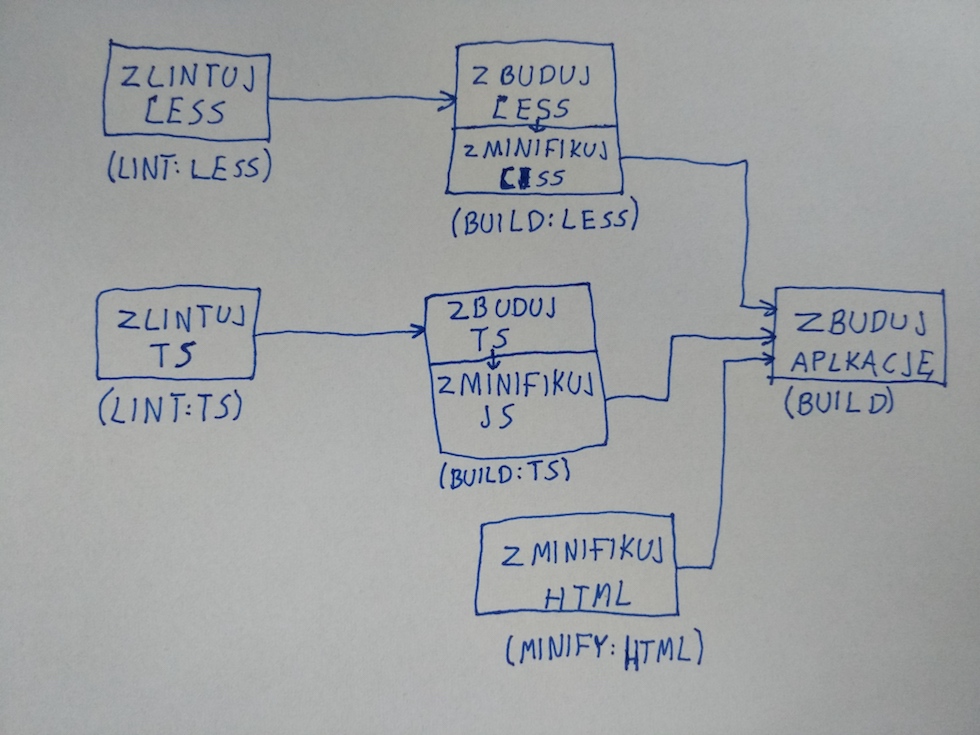
Zadania, które muszą zostać wykonane przed rozpoczęciem bieżącego zadania podajemy jako drugi parametr funkcji gulp.task():
gulp.task('default', ['build']);
gulp.task('build', ['build:less', 'build:ts'], () => {
log('Finished build');
});Obserwowanie zmian w plikach
Pracując nad aplikacją zwykle potrzebujemy ją przebudować po zmianie w plikach źródłowych. Gulp oferuje możliwość śledzenia zmian na plikach, w związku z czym możemy wywołać callback. Warto jest także dodać zadanie budowania aplikacji jako zależność watcha.
gulp.task('watch', ['build'], () => {
gulp.watch('src/less/*.less', ['build:less']);
gulp.watch('src/ts/*.ts', ['build:ts']);
});Ekstrakcja ścieżek i danych dostępowych
W pliku gulpfile.js znajduje się wiele różnych ścieżek. Część z nich służy do przeszukiwania plików źródłowych. Część jest ścieżką dla plików wynikowych. Do tego dochodzą różnego rodzaju dane dostępowe, np. hasła do ftp, klucze do chmury. Żeby zapanować nad tym chaosem, możemy wydzielić ścieżki i dane dostępowe do odrębnych plików. Osobiście ścieżki wyciągam do gulp.config.js, a dane dostępowe do secrets.json.
gulp.config.js
module.exports = function () {
'use strict';
const buildPath = './dist/';
var config = {
buildPath: buildPath,
buildCssPath: buildPath + 'css/',
lessBuildFiles: [
'./src/*.less'
],
lessWatchFiles: [
'./src/**/*.less'
]
};
return config;
}secrets.json
{
"azureBlobStorage": {
"account": "(...)",
"key": "(...)",
"container": "(...)"
},
"azureFtp":{
"host": "(...)",
"user": "(...)",
"password": "(...)",
"remotePath": "(...)"
}
}Po utworzeniu tych plików jesteśmy w stanie uzyskać do nich dostęp w gulpfile.js:
var config = require('./gulp.config.js')(),
secrets = require('./secrets.json');
// (...)
return gulp.src(config.lessBuildFiles)
.pipe(less())
.pipe(autoprefixer({
browsers: ["last 2 version"]
}))
.pipe(concat('main.min.css'))
.pipe(cleanCss())
.pipe(gulp.dest(config.buildCssPath));Na deser zostało jeszcze zmniejszenie liczby upierdliwych require. Za pomocą gulp-load-plugins usuwamy wszystkie załączenia pluginów z nazwą gulp-*.
/* PRZED */
var gulp = require('gulp'),
autoprefixer = require('gulp-autoprefixer'),
less = require('gulp-less'),
concat = require('gulp-concat'),
cleanCss = require('gulp-cleancss');
// (...)
.pipe(cleanCss())
/* PO */
var gulp = require('gulp'),
$ = require('gulp-load-plugins')();
// (...)
.pipe($.cleanCss())Podsumowanie
W wyniku wszystkich wymienionych operacji dostaliśmy następujący gulpfile:
var gulp = require('gulp'),
config = require('./gulp.config.js')(),
secrets = require('./secrets.json'),
$ = require('gulp-load-plugins')();
gulp.task('default', ['build']);
gulp.task('build', ['build:less']);
gulp.task('watch', ['build'], () => {
gulp.watch(config.lessBuildFiles, ['build:less']);
});
gulp.task('build:less', () => {
return gulp.src(config.lessBuildFiles)
.pipe($.less())
.pipe($.autoprefixer({
browsers: ["last 2 version"]
}))
.pipe(concat('main.css'))
.pipe($.cleanCss())
.pipe(concat('main.min.css'))
.pipe(gulp.dest(config.buildCssPath));
});Nie jest to kod pasujący do każdej sytuacji, ale może stanowić podstawę do Twojego pierwszego skryptu automatyzującego.
Cały projekt umieściłem na Githubie. Możesz się nim pobawić, żeby poczuć w jaki sposób działa Gulp.

